罗 浩,王彦捷,牛明航,邱存月,张 利
辽宁大学 信息学院,沈阳110036
1 引言
进入信息时代,数据激增,随时都能积累大量数据,为了充分挖掘数据中的价值,对数据进行聚类分析是一种有效的方法。模糊C 均值(fuzzy C-means,FCM)是一种应用最广泛、最成熟的聚类算法,但是模糊C 均值算法的局限性是不能处理不完整的数据集,需要把不完整的数据集填充完整才能聚类分析[1]。在数据采集过程中由于噪声干扰、传感器异常等原因不可避免地产生不完整数据,这对聚类造成很大影响,因而也成为一个研究热点。
为解决不完整数据的模糊C均值聚类问题,许多学者提出了对缺失属性估值填补的改进算法[2-9]。其中文献[5]构造了一种高斯RBF(radial basis function)核函数,对样本中的缺失属性进行填充。文献[6]提出一种新的贝叶斯估值算法对缺失数据进行估值填补。文献[7]提出一种新的模糊聚类规则模型,利用中智模糊聚类得到的隶属度矩阵生成初始模糊规则,能够有效处理数据中的噪声,整体提高模型的逼近性。文献[8]以互信息为依据对数据集中的属性进行排序,充分考虑了数据集中与位置相关的属性值特征,对排序后的不完整数据集进行估值填充。文献[9]提出基于稀疏表示的混合属性数据填补方法,将局部约束线性编码和局部约束稀疏编码引入到最近邻样本构建过程,更好地保留了数据的局部结构特征。
随着对估值填补算法的深入研究,发现使用区间型数据能够进一步提高不完整数据聚类的模糊性和鲁棒性[10-12]。文献[10]提出一种改进BP(back propagation)神经网络的区间填补不完整数据聚类算法,通过神经网络对缺失属性进行区间范围填补。文献[11]提出一种区间型核函数模糊聚类算法,利用最近邻规则确定缺失属性区间,使用核函数模糊C均值对样本进行高维映射和聚类。文献[12]提出一种区间型模糊协同聚类算法,将区间型数据应用于协同聚类使聚类结果更加准确。
为了减小离群点对聚类中心的影响,结合近邻区域内样本的数量,一些学者也提出新的加权聚类算法。文献[13]提出一种自然最近邻优化的密度峰值聚类算法,根据样本局部分布密度峰值及稀疏区域划分的特点确定聚类中心。文献[14]提出一种基于超球面密度的聚类算法,能够更快获得位于数据密集区域的初始聚类中心,从而加速算法收敛。文献[15]提出一种基于约束性密度峰的快速搜索聚类算法,充分利用约束条件下的结构信息,快速获取密度度量从而加速聚类。文献[16]提出一种自适应区间加权聚类算法,动态调整区间样本的关联权值来明确不同区间样本对聚类中心的贡献大小。
借鉴上述学者的研究,提出一种动态区间的加权模糊聚类算法(dynamic interval weighted interval fuzzy C-means clustering algorithm,DI-WIFCM)。首先,根据属性相关度计算缺失样本和其他样本之间的距离,确定最近邻样本集,从而确定缺失属性区间大小。为减少最近邻样本区间填补缺失属性的误差,提出区间因子来控制填补缺失数据区间的大小,实现动态区间填补对应的缺失属性,将不完整数据集转化为完整的区间型数据集。其次,为减小样本离群点对聚类的影响,提高聚类准确率,对区间型样本赋予权值。权重通过计算样本在近邻区域内的密度得到,密度越大权值越大,反之权值越小,增强中心样本对迭代过程中聚类中心选取的影响程度,减弱离群点对聚类中心点选取的影响。最后进行区间型加权聚类分析。在多个UCI 数据集和人工数据集上与四种经典算法[17]和近年来的几种同类算法比较,验证本文算法的有效性。
2 模糊聚类算法
聚类是将数据对象分为多个不相交的类(称为簇)的过程,同一个类中的对象彼此之间具有很高的相似性,而不同类中属性差异明显。FCM 算法是运用最普遍、最成熟的聚类算法,在语音识别[18]、模型辨别[19]、模糊决策[20]和控制[21]等领域得到广泛应用。本章主要是对FCM 算法和区间型FCM 算法(interval fuzzy C-means,IFCM)进行的算法分析。
2.1 FCM聚类算法
FCM 是一种很成熟的聚类算法,包含三个基本算子:模糊隶属度函数、分类中心矩阵和目标函数。首先,建立极小化目标函数;其次,利用迭代的思想,优化目标函数极小化;最后,根据每个样本依据隶属度的大小判断自己将隶属于哪一类。
2.2 区间型FCM聚类算法
区间型FCM 聚类(IFCM)的数据均是区间型数据集[22-23]。设属性维度为s的区间型数据集,被分为c类。每个数据都是区间型,表示 为,其中,1≤j≤s。区间型模糊C均值算法的目标函数公式如式(1)所示:
![图片[1]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195048-68755f98c01b3.webp)
隶属度uik的约束条件如式(2)所示:
![图片[2]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195051-68755f9b4d5d8.webp)
区间样本xk与聚类中心vi的欧式距离计算如式(3)所示:
![图片[3]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195053-68755f9d16b83.webp)
其中,区间样本xk的属性区间上界向量与下界向量分别为:
![图片[4]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195055-68755f9f1bba3.webp)
聚类中心的区间上界向量和下界向量分别为:
![图片[5]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195057-68755fa192b9a.webp)
区间型聚类中心的更新如式(4)、式(5)所示:
![图片[6]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195101-68755fa50370d.webp)
![图片[7]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195103-68755fa716d66.webp)
![图片[8]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195104-68755fa89772b.webp)
2.3 区间型FCM聚类算法流程
IFCM算法的基本步骤如下所示:
步骤1初始化算法参数:设定迭代停止阈值ε,模糊聚类参数m,聚类的类别数c(2≤c≤),最大迭代次数G,初始化隶属度矩阵U(0)。
步骤2更新聚类中心矩阵:当迭代到第l次时,结合隶属度划分矩阵U(l-1),利用聚类原型计算公式(4)和式(5)更新聚类中心矩阵。
步骤3更新隶属度矩阵:利用式(6)和式(7)更新划分隶属度矩阵U(l)。
步骤4算法终止迭代条件:当迭代次数达到最大值时,或时停止迭代,则FCM 算法停止,输出划分矩阵U和聚类原型矩阵;否则l=l+1,返回步骤2。
上述IFCM算法的时间复杂度为O(Gnsc),其中G为迭代最大次数,n为样本个数,s为样本维数,c为聚类中心个数。
3 不完整数据动态区间估计
根据最近邻规则[24]提出一种新的样本间属性相关度计算方法,计算不完整数据和其他数据之间的相关度,构建出不完整数据的最近邻样本集。依据最近邻样本的属性取值范围预测不完整样本缺失属性的区间范围。为进一步减小区间取值带来的误差,提出动态控制区间大小的区间因子,通过最近邻样本的离散度确定的区间因子来控制对应区间的大小,即对不完整样本的动态区间填补。
3.1 近邻样本的选取
由于近邻样本间有着很高的相似性,因此对于缺失属性的填补具有很好的指导性。在数据挖掘中,余弦相似性用来计算两个对象之间的相似程度,计算得到的数值越大,说明对象间相似性越高[25]。对于任意的两个随机变量A、B,两个变量之间的余弦相似性计算如式(8)所示:
![图片[9]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195106-68755faa2d9ce.webp)
式中,Ai和Bi分别代表变量A和B中的第i个数据。
对于一个属性维度为s的不完整数据集X={x1,x2,…,xn},X中至少存在一个样本的某个属性是缺失的,缺失属性的样本不能缺失该样本的全部属性,同时数据集中所有的样本不能都缺失某种属性。对于不完整数据集中的样本xk和样本xp相似性度量的计算,根据余弦相似定理本文提出的属性相关度计算公式如式(9):
![图片[10]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195108-68755fac396c6.webp)
式中,xjk和xjp分别代表样本xk和样本xp中的第j个属性,m代表要填补的属性,cos(jm)表示第j个属性和第m个属性之间的相关度。
Ij的计算如式(10)所示:
![图片[11]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195110-68755faec1fe6.webp)
其中,k,p=1,2,…,n,j=1,2,…,s。
3.2 动态区间估计
3.2.1 区间因子的机制
在区间分析法中,设有区间型变量X=[x-,x+],其中x-为区间最小值,x+为区间最大值,Xc=为区间中值,Δx=×α为区间变量宽度。则X=[x-,x+]=[Xc-Δx,Xc+Δx],其中α为区间因子,区间因子用来控制区间范围的大小。对于任意已知上下限的区间变量,均可通过控制区间因子的大小,进而约束区间变量X的大小。
为了进一步提高算法的准确率,降低区间大小对模糊聚类结果准确率的干扰,提出动态控制区间范围的区间因子,对缺失属性填补区间进行控制。近邻样本都具有很高的相似性,因而最近邻样本集中样本的分布也能体现属性的分布情况。对于不完整样本的待填充属性,其最近邻样本集的离散度反映了样本远离预测中心的程度,样本密集则区间因子控制的属性估值区间减小。
3.2.2 区间因子的计算
区间因子由缺失样本的最近邻样本离散度决定,区间因子α的计算如式(11)所示:
![图片[12]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195113-68755fb1369f7.webp)
其中,β表示样本集的离散程度,β的计算如式(12)所示:
![图片[13]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195115-68755fb3ac33f.webp)
![图片[14]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195118-68755fb631500.webp)
3.2.3 区间大小的确定
对缺失属性xkj,通过提出的属性相关度计算公式(9)构造最近邻样本集,并确定填补区间。
为进一步减小区间化填补数据的误差,利用最近邻样本集中样本分散程度计算出的区间因子来控制填补区间的大小,即,新的填补区间为。
例如,通过xkj最近邻样本集确定的填补区间[1,3],区间中值=2,若样本集较发散,区间因子α=0.9,则新填补区间为[1.1,2.9];若样本集较密集,区间因子α=0.3,则新填补区间为[1.7,2.3],从而对缺失属性进行动态区间填补。
4 加权模糊聚类算法
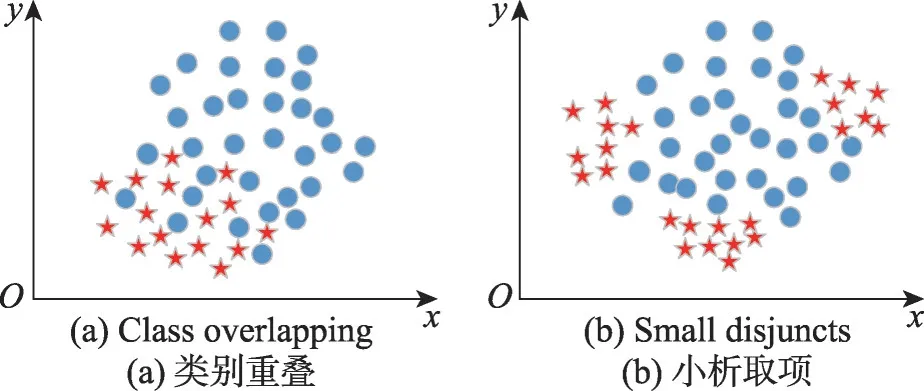
同类样本具有很高的相似度,因而同类样本间距离较近,在属性空间中密度大。传统样本的权值计算是一种基于距离的计算,通过该样本和聚类中心的距离或者和其他样本之间的距离对其进行权值计算,没有考虑区域内样本个数或密度。同时数据集中存在一些与聚类中心距离远的离群点,它们不能有效反映出类别信息,影响聚类中心的选择和聚类迭代的稳定性。针对以上问题提出一种新的基于区域密度加权的聚类算法。对传统权值计算进行改进,将样本的近邻区域内同类样本的密度引入聚类权值的计算,从而避免了单一距离的计算,同时减少离群点对聚类中心的影响。
4.1 区域密度加权算法
区域密度加权算法通过统计数据样本点在近邻区域内其他样本点的个数,进而对该样本赋予权值[26]。s维数据集X={x1,x2,…,xn},其权值计算过程如下:
首先确定数据的统计范围,如式(14)所示:
![图片[15]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195120-68755fb893959.webp)
其中,yj代表数据集中的第j个属性,∙2代表范数。样本xp和其他样本之间的距离计算如式(15)所示:
![图片[16]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195122-68755fbac6117.webp)
权值的计算公式如式(16):
![图片[17]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195125-68755fbd5d66f.webp)
其中,mp代表数据xp一定范围内近邻点的个数,计算公式如式(17)和式(18)所示:
![图片[18]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195127-68755fbf3177b.webp)
4.2 区间型数据权值计算
对数值型数据权值赋予方式进行改进,提出适用于区间型数据的权值赋予方式,改进如下:
对于有样本总数为n的s维区间型数据集,样本的每个属性都是区间型数据,对于任意的数据表示形式为,其权值计算过程如下:
确定数据的统计范围,如式(19)所示。
![图片[19]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195129-68755fc17a3de.webp)
样本xp和其他样本之间的距离计算如式(20)所示:
![图片[20]-动态区间的加权模糊聚类算法*-游戏花园](http://www.hunggame.com/wp-content/uploads/2025/07/20250714195131-68755fc376a97.webp)
4.3 区间型加权模糊聚类模型
由于数据自身存在离群点的问题,填补后的区间型数据集仍有部分离群点的存在,为进一步减小区间值的误差,增加区间数据集聚类的精度,本文对区间型模糊C均值的迭代过程进行了改进,把权值加入到区间型模糊C均值的迭代过程中。
设属性维度为s的区间数据集。数据,对于任意的j(1≤j≤s),,区间型模糊C均值算法的目标函数如式(21)所示:
![图片[21]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035024dgggdi5b14m.webp)
其中,隶属度uik的约束条件如式(22)所示:
![图片[22]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035024sg4horog4oc.webp)
区间型数据与聚类中心的计算如式(23)所示:
![图片[23]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035024mazwt2v0tka.webp)
其中,φk表示样本xk的权值,同时表示第i个聚类中心,为聚类中心矩阵。
利用拉格朗日乘子法增广泛函得式(24)。
![图片[24]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350241xlsfgfvct1.webp)
对式(24)进行最优解求导得式(25)、式(26):
![图片[25]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035025vu1uf434slu.webp)
对式(26)求解得式(27):
![图片[26]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035025uphdrkgbdd0.webp)
将式(27)带入式(25)后i改为t得式(28):
![图片[27]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350254t31vsqv04i.webp)
![图片[28]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035025ti0qb0r24la.webp)
进行最优解求导得式(30):
![图片[29]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035025jz3xvi00fo2.webp)
![图片[30]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350255bu1qowp310.webp)
4.4 DI-WIFCM聚类算法流程
DI-WIFCM算法的具体流程如下:
步骤1确定最近邻样本数:通过最近邻规则确定最近邻样本数q。
步骤2计算最邻近样本:根据式(8)、式(9)和式(10)的属性距离相似度计算公式,确定待填补数据的最近邻样本。
步骤3填补缺失属性:利用式(11)、式(12)和式(13)计算区间因子,把数据改成区间的形式进行填补。
步骤4初始化参数:设定迭代停止阈值ε,模糊聚类参数m,聚类的类别数c(2≤c≤),最大迭代次数G,初始化隶属度矩阵U(0)。
步骤5计算样本权值:通过式(16)对样本进行加权。
步骤6更新聚类中心矩阵:当迭代到第l次时,结合隶属度划分矩阵U(l-1),利用聚类原型计算公式(31)和(32)更新聚类中心矩阵。
步骤7更新隶属度矩阵:根据聚类中心矩阵,利用式(29)更新隶属度矩阵U(l)。
步骤8算法终止迭代条件:当迭代次数达到最大值时,或时停止迭代,则聚类算法停止,输出划分矩阵U和聚类中心矩阵V;否则l=l+1,返回步骤6。
上述DI-WIFCM 算法中,不完整数据的动态区间填充的时间复杂度为O(kn),样本加权的时间复杂度为O(n2),DI-WIFCM 算法的时间复杂度为O(kn+n2+Gnsc),其中k为不完整样本个数,n为样本个数,G为迭代最大次数,s为样本维数,c为聚类中心个数。
5 实验结果及分析5.1 数据集及实验参数选取
本文选取UCI 数据集中的三个数据集(Iris、Breast、Bupa)和两个人工数据集(Test1、Test2)作为实验样本。这三个UCI 数据集信息的相关描述如表1所示。
![图片[31]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035025j0cfj05aanq.webp)
Table 1 Description of UCI dataset表1 UCI数据集描述
相关实验中的参数设置如下:区间模糊C均值算法的模糊化参数m=2,迭代停止阈值ε=10-5,最大迭代次数G=100,设置数据集的随机缺失比例为5%、10%、15%和20%,为减小缺失数据的随机生成的不确定性给聚类结果带来的影响,每个算法运行10次的结果取平均值,最优结果和次优结果分别用加粗和加下划线标出。两个人工数据集参数设置如表2所示。
![图片[32]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026ch4ho12yak0.webp)
Table 2 Parameters of artificial dataset表2 人工数据集参数
5.2 实验对比结果
每种算法在不同数据集上进行多次实验后的结果如表3~表11所示。
![图片[33]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026xonddqywkeq.webp)
Table 3 Averaged number of misclassification using incomplete Iris dataset表3 不完整数据集Iris的平均聚类错分数
![图片[34]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026kimo21jtujz.webp)
Table 4 Averaged number of misclassification using incompleted Breast dataset表4 不完整数据集Breast的平均聚类错分数
![图片[35]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026wvlt1efrf1e.webp)
Table 5 Averaged number of misclassification using incompleted Bupa dataset表5 不完整数据集Bupa的平均聚类错分数
![图片[36]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026sneahdbeqm2.webp)
Table 6 Averaged number of iteration using incompleted Iris dataset表6 不完整数据集Iris的平均迭代次数
![图片[37]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026eopftcwlxm0.webp)
Table 7 Averaged number of iteration using incompleted Breast dataset表7 不完整数据集Breast的平均迭代次数
![图片[38]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026kltwdqxgjdn.webp)
Table 8 Averaged number of iteration using incompleted Bupa dataset表8 不完整数据集Bupa的平均迭代次数
![图片[39]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026flmw5z0e3wp.webp)
Table 9 Averaged standard deviation of misclassification using incompleted Iris dataset表9 不完整数据集Iris的平均聚类错分数标准差
![图片[40]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035026ynuh3wudmq0.webp)
Table 10 Averaged standard deviation of misclassification using incompleted Breast dataset表10 不完整数据集Breast的平均聚类错分数标准差
![图片[41]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027zh3kmox5lwe.webp)
Table 11 Averaged standard deviation of misclassification using incompleted Bupa dataset表11 不完整数据集Bupa的平均聚类错分数标准差
在本文的算法对比实验中,完备数据策略模糊C均值聚类算法(whole data strategy fuzzy C-means clustering,WDS-FCM)和局部距离策略模糊C 均值聚类算法(partial distance strategy fuzzy C-means clustering,PDS-FCM)是舍弃法。WDS-FCM 算法把数据集中不完整的样本数据全部剔除,只对完整的样本数据进行模糊聚类,算法在不完整样本比例增大时聚类精度会受到很大影响。PDS-FCM算法将不完整样本数据中的完整属性加入迭代运算,未考虑不完整样本缺失的属性信息,没有充分发挥不完整样本的信息价值。其余的两种算法,优化完整策略模糊C 均值聚类算法(optimal completion strategy fuzzy C-means clustering,OCS-FCM)、最近原型策略模糊C均值聚类算法(nearest prototype strategy fuzzy C-means clustering,NPS-FCM)对数据的处理方式都属于估值法。OCS-FCM 算法将缺失属性看作待优化变量,在聚类中心和隶属度矩阵迭代更新过程中同步更新缺失属性,但是算法需要反复迭代更新缺失属性值,使算法迭代次数增加。NPS-FCM算法用不完整样本的最近聚类中心对应的属性值来填补缺失的属性值,然后继续参与算法迭代。随着迭代次数的增加,估值的误差会被放大,同时两个估值算法都没有考虑近邻样本会对缺失属性的填补起到很好的指导作用,也没有考虑到样本属性彼此之间的关联。
从表3~表5中平均聚类错分数来看,DI-WIFCM算法在每个数据集中都取得了最好的结果,平均聚类错分数作为最重要的聚类算法评价指标,说明DIWIFCM 有很好的聚类准确率。且样本随着缺失率的增加平均聚类错分数相对于其他算法进一步降低,说明DI-WIFCM 算法中区间因子对区间范围的约束有效性高,随着数据缺失比例的增加,更能体现数据的信息价值,有着很强的适应能力。
从表6~表8 中平均迭代次数来看,DI-WIFCM算法在大多数情况下没有取得最少迭代次数的结果。DI-WIFCM算法较其他对比算法计算复杂,但是经过一定次数迭代后也能取得稳定收敛。
从表9~表11 中错误分类标准差来看,相对于其他不完整数据算法,DI-WIFCM 有着较低的标准差。证明本文算法在不完整数据聚类方面有很高的准确性和鲁棒性。
图1~图3 是DI-WIFCM 算法在进行不完整数据聚类时,在三种数据集下目标函数迭代变化趋势图,可以看出在不同情况下算法迭代都很稳定。
![图片[42]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027id20im3xlm0.webp)
Fig.1 Iteration graph of DI-WIFCM in Iris图1 Iris中DI-WIFCM聚类迭代图
![图片[43]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027m2ypnuirfqa.webp)
Fig.2 Iteration graph of DI-WIFCM in Breast图2 Breast中DI-WIFCM聚类迭代图
![图片[44]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350272iid4k4zja4.webp)
Fig.3 Iteration graph of DI-WIFCM in Bupa图3 Bupa中DI-WIFCM聚类迭代图
将最近几年不完整数据处理算法区间监督的混杂蚁群优化聚类算法(interval supervision hybird ant colony optimization fuzzy C-means clustering algorithm,IS-HAC)[27]、缺失属性区间大小调控的模糊C均值聚类算法(missing attribute interval size fuzzy C-means clustering algorithm,MIS-FCM)[28]、改进遗传优化的局部加权模糊C 均值聚类算法(improved genetic optimized local weighted fuzzy C-means clustering algorithm,GLW-FCM)[29]、信息反馈RBF 网络估值的区间型模糊C 均值聚类算法(information feedback RBF network interval estimation fuzzy C-means clustering,IFRBF-IFCM)[30]与本文算法在UCI 数据集下进行对比实验。
从表12~表14 中平均聚类错分数来看,DIWIFCM在整体上优于其他算法。从表15~表17中聚类错分数标准差来看,DI-WIFCM算法多次取得最优解,尤其在Breast 中三种情况下得到最小值,整体性能及稳定性优于其他算法。
![图片[45]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027hw3ueglfhi1.webp)
Table 12 Averaged number of misclassification of five improved FCMs in incompleted Iris dataset表12 五种改进FCM算法在不完整数据集Iris中平均聚类错分数
![图片[46]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027ctcvugsjugk.webp)
Table 13 Averaged number of misclassification of five improved FCMs in incompleted Breast dataset表13 五种改进FCM算法在不完整数据集Breast中平均聚类错分数
![图片[47]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035027zda3br0jsy3.webp)
Table 14 Averaged number of misclassification of five improved FCMs in incompleted Bupa dataset表14 五种改进FCM算法在不完整数据集Bupa中平均聚类错分数
![图片[48]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350282ftjnok5jhh.webp)
Table 15 Standard deviation of misclassification of five improved FCMs in incompleted Iris dataset表15 五种改进FCM算法在不完整数据集Iris中聚类错分数标准差
![图片[49]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028uix04texnwn.webp)
Table 16 Standard deviation of misclassification of five improved FCMs in incompleted Breast dataset表16 五种改进FCM算法在不完整数据集Breast中聚类错分数标准差
![图片[50]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028z3whn03j5lr.webp)
Table 17 Standard deviation of misclassification of five improved FCMs in incompleted Bupa dataset表17 五种改进FCM算法在不完整数据集Bupa中聚类错分数标准差
从图4~图6 中可以看出DI-WIFCM 算法在大部分情况均取得最优值。基于蚁群优化的不完整数据聚类算法(IS-HAC)与信息反馈式的RBF网络填充算法(IFRBF-IFCM)都是构造模型通过最近邻样本集对不完整数据进行估值填充,然而其估值的不确实性限制了算法的鲁棒性。区间分析模糊聚类算法(MIS-FCM)和局部加权的不完整数据聚类算法(GLW-FCM)对不完整数据进行区间化模糊处理和加权聚类,但是没有考虑样本集中离群点对聚类中心的影响,因而聚类准确性不高,迭代过程不稳定。
为验证DI-WIFCM算法的泛化性,将DI-WIFCM算法应用于两个人工数据集(Test1 和Test2)进行测试,如表18~表20所示。
从表18~表20中可以看出,DI-WIFCM算法在不同数据集聚类效果良好,泛化性强。从图7、图8中可以看出,在不同人工数据集中,DI-WIFCM 算法经过一定迭代次数能够很快达到收敛。
本文所提出的DI-WIFCM 算法充分利用了不完整数据的属性特征,确定的最近邻样本集能够很好估计缺失属性的范围,进而实现缺失属性的区间填补,同时使用区间因子对区间范围进行更好的约束。对样本进行区域密度加权,从而减小离群点对数据聚类中心的影响,使聚类迭代过程更稳定。通过实验证明,对于不完整的数据的聚类问题,DIWIFCM算法聚类效果更好。
![图片[51]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028oymsxlvtge4.webp)
Fig.4 Comparison of clustering algorithms in Iris图4 Iris中聚类算法对比图
![图片[52]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028ocghmqbqnfj.webp)
Fig.5 Comparison of clustering algorithms in Breast图5 Breast中聚类算法对比图
![图片[53]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028xuwa4spmfa2.webp)
Fig.6 Comparison of clustering algorithms in Bupa图6 Bupa中聚类算法对比图
![图片[54]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035028l4vmjpeydbf.webp)
Table 18 Averaged number of misclassification using incompleted artificial dataset表18 不完整人工数据集中平均聚类错分数
![图片[55]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350292xgbtlighvg.webp)
Table 19 Averaged number of iteration using incompleted artificial dataset表19 不完整人工数据集中平均迭代次数
![图片[56]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/20250715035029evwud3xnaru.webp)
Table 20 Averaged standard deviation of misclassification using incompleted artificial dataset表20 不完整人工数据集中平均聚类错分数标准差
![图片[57]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350290xudndwfdem.webp)
Fig.7 Iteration graph of DI-WIFCM in Test1图7 Test1中DI-WIFCM聚类迭代图
![图片[58]-动态区间的加权模糊聚类算法*-游戏花园](images/2025/07/202507150350295qoq5bwfbm3.webp)
Fig.8 Iteration graph of DI-WIFCM in Test2图8 Test2中DI-WIFCM聚类迭代图
6 结束语
针对不完整数据聚类的问题,本文提出动态区间的加权模糊聚类算法(DI-WIFCM),根据最近邻规则确定待填补样本的最近邻样本集,通过最近邻样本集中属性值的离散程度确定区间因子,从而动态调整缺失属性的估值区间。为减小离群点对模糊聚类的影响,进一步提高算法的精度,算法对样本赋予基于密度的权值,并加入到模糊聚类的迭代过程中,使聚类迭代过程更稳定。本文采用三个UCI 数据集和两个人工数据集对提出的DI-WIFCM 算法进行检验,结果表明算法具有较高的准确率。