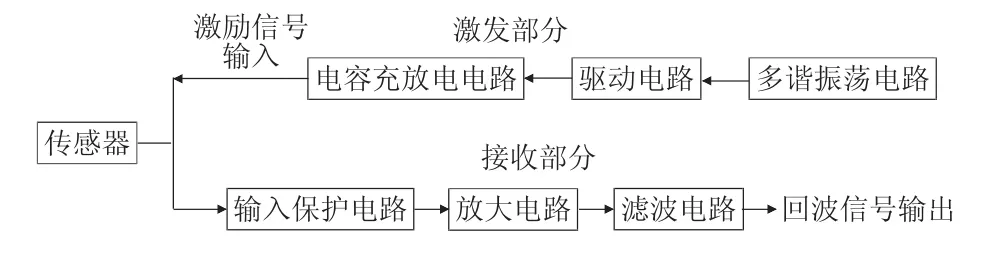
李 超,门昌骞,王文剑
1.山西大学 计算机与信息技术学院,太原030006
2.计算智能与中文信息处理教育部重点实验室(山西大学),太原030006
1 引言
强化学习是基于自然界动物试错学的一种学习方法。在强化学习中,智能体(Agent)采取动作不断与环境进行交互,通过观测到环境的变化以及接收环境返还给它的奖励,从这些反馈之中学习到一个动作序列,通常称之为策略。Agent 的目标就是学习到一个最优策略,在它根据此最优策略与环境进行交互时,所获得的累积奖励最大化。策略是状态到动作的映射,Agent 可以在具体的状态处根据策略选取相应的动作。根据Agent 学习策略方式的不同强化学习方法大致分为基于策略搜索的强化学习方法、行为-评判器方法(Actor-Critic)以及基于值函数的强化学习方法。基于策略搜索的强化学习方法和Actor-Critic 方法将策略参数化,通过求解最优参数进而寻找最优策略,适用于具有高维连续动作空间的强化学习问题。相比之下基于值函数的强化学习方法更适用于具有低维离散动作空间的强化学习问题[1]。
基于值函数的强化学习方法通过评估每个状态的状态值或者每个状态行为对的状态行为值来学习最优策略,分为表格法和值函数逼近的方法。前者通过遍历所有的状态行为对,建立一张状态行为值表,之后根据该表中的数据进行策略的学习;后者通过函数逼近的方法来计算状态值函数或者状态行为值函数,但是对函数逼近器的逼近能力和泛化能力要求极高,且函数逼近方法一般难以收敛[1],因此在表格法的基础上开展值函数学习的研究仍具有重要的应用价值。表格法在状态空间和动作空间规模较小的问题中表现出了极好的收敛性,当状态空间和动作空间很大甚至连续时,不可能穷举出所有的状态行为对并计算相应的值,此时就需要对状态空间进行离散化划分,以此建立状态行为值表,之后对该表进行更新,用表中已有的状态行为值去评估未知状态行为值,最终学到最优策略。传统的状态离散化方法对整个状态空间进行等精度划分,实际上求取最优策略并不需要在整个状态空间上进行学习,Barto 等人指出只需要在相关状态上进行尝试就可以学到最优策略[2]。对于等精度划分得到的离散状态空间,Lin 等人估计,当学习完成后,与最优决策相关的状态数不到整个离散状态空间的25%[3]。因此对于整个状态空间进行等精度划分是不必要的,相比等精度划分,自适应状态划分法可以根据需要对状态空间进行变精度划分,从而降低空间复杂度。自适应状态划分法主要分为两类:一类是离散状态总数固定的方法,即划分状态总数固定,各状态范围可调整,这类方法有径向基调整法[4]、自组织网络法[5]等,但划分状态总数如果过多,则空间复杂度变大,学习速率减慢;总数过少,学习效果变差。另一类是事先规定离散状态阈值,在线学习过程中如果遇到的状态与已有离散状态距离大于此规定阈值,则将此状态添加为离散状态,这类方法有径向基生长法[6]、基于树的表示方法[7]等。
探索与利用的均衡一直是强化学习研究的核心问题之一。在强化学习算法执行过程中,探索未知的状态行为空间可能会产生比当前更优的决策;同时利用则是根据当前已经学到的知识来产生当前最优决策,合理分配探索和利用的比重会对强化学习结果产生重大的影响。其中启发式探索方法近期取得了巨大的成功,比如ϵ-greedy 在DQN(deep Q network)以及DQN的一系列变种方法中表现出了优异的成果[8],但是启发式探索方法在探索时随机选取非最优动作,不考虑次优动作以及其余动作的不确定性,探索效率低下;而且启发式探索方法通常需要大量的数据和时间才可以产生优秀的结果。针对启发式探索方法这些缺点,PAC(probably approximately correct)最优探索算法极大地提升了探索的效率,但是传统的PAC 最优探索算法仅仅适用于低维离散状态空间和动作空间强化学习问题,在状态空间和动作空间很大甚至连续的问题上,传统PAC 最优探索算法并不适用[9]。
综合状态空间自适应离散化划分和探索与利用的均衡这两个问题,本文提出了基于状态空间自适应离散化的RMAX-KNN 强化学习算法,该算法经理论证明是一种PAC 最优探索算法,可以在短时间内逼近最优策略,并且该算法可以在有效探索状态空间的同时实现对状态空间的自适应离散化。此外,在三个常见的benchmark 环境上测试此算法,结果表明本文算法是可行且高效的。
2 背景知识
为了更好地了解本文算法,在阐述算法之前简单介绍一下值函数的相关定义以及时间差分算法。
2.1 状态值函数和状态行为值函数
强化学习中Agent 与环境不断进行交互的过程可以理解为一个序贯决策问题,即不断进行决策的问题,这里的决策就是Agent 从交互数据中学到的策略。这一过程可以抽象为一个马尔可夫决策过程(Markov decision process,MDP)。马尔可夫决策过程MDP 可以表示为一个五元组,其中S表示有限的状态集,A表示有限的动作集,R表示回报函数,P表示状态转移概率,γ表示折扣因子。在定义好MDP 之后,强化学习的学习过程就可以表示为s0a0r1s1a1…statrt+1st+1,在这里假设st+1为终止状态,此时强化学习的目标就是找到一个最优策略π(as)来使累积折扣回报G=r1+γr2+γ2r3+…+γtrt+1最大化,这里的策略π(as)是一个函数,对于状态集S中的每一个状态s,π(as)表示了在当前状态s选取动作a的概率,即π(as)=P(At=aSt=s)。
基于值函数的强化学习方法通过评估每个状态或者状态行为对的价值然后选择策略,其中状态值函数表示从当前状态开始依照当前策略期望的返还,即Vπ(s)=Eπ(GtSt=s);状态行为值函数表示从当前状态执行某个动作之后遵循当前策略期望的返还,即Qπ(s,a)=Eπ(GtSt=s,At=a),其中Gt=rt+1+γrt+2+γ2rt+3+…+γkrt+k+1,表示了某一时间步t时的累积回报[1]。当算法学习到最优状态值函数V*(s)或者最优状态行为值函数Q*(s,a)时,值函数满足贝尔曼最优方程,贝尔曼最优方程如下:
![图片[1]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172502-686ff76e9098b.webp)
2.2 时间差分算法
时间差分算法是基于值函数的强化学习方法中的核心算法[1],其更新公式为:
![图片[2]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172504-686ff77049b58.webp)
根据行为策略和评估策略是否一致,时间差分方法分为两大主流算法Q-learning和Sarsa,Q-learning的学习目标为:
![图片[3]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172505-686ff7719523f.webp)
Sarsa的学习目标为:
![图片[4]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172507-686ff773189ac.webp)
3 RMAX-KNN 算法
算法分为状态空间学习和值函数学习两部分,这两部分同步进行。在Agent 与环境交互的过程中,通过判断新状态与已有离散状态的最小距离是否大于某一阈值来决定是否添加此新状态为新的状态空间代表点,这一部分被称为状态空间学习;同时,通过状态空间学习学习到的状态空间表示点在值函数学习过程中被用来衡量状态的已知程度。根据当前状态已知程度计算相应的状态行为值,并根据此值进行动作选择并转移到下一状态;同时根据下一状态的已知程度计算出相应的更新量,最终对已学到的状态空间表示点的状态行为值进行更新,值函数计算和值函数更新合称为值函数学习。
3.1 相关假设与状态空间学习
假设1 确定性状态转移函数和已知的回报函数。假设当前状态为s,执行动作a,则P(s′s,a)=1 且,同时已知且非负,同时Rmax。当然也可以类推出状态转移函数不确定时的情况。
假设2值函数满足利普希茨连续条件,即存在常数LQ,满足Q(s,a)-Q(s′,a)≤LQd(s,a,s′,a)。在连续状态空间MDP 中,同一状态行为对很难出现第二次,当值函数满足利普希茨连续条件时,就可以用该状态行为对“旁边”的状态行为对代替此状态行为对来进行值函数学习,同时不会造成太大的误差。
算法单独设置一个存放状态空间表示点的列表D,初始化为空,同时设置一个距离阈值d_target来决定是否应该添加新的状态空间表示点到此列表中,以及一个最大离散状态数Nmax。在Agent 与环境交互的过程中,假设某一时刻状态为s,此时判断式(1)是否成立,如果成立,则将s添加入D中;若不成立,则说明D中已有可以表示状态s的代表点或者D已满。
![图片[5]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172508-686ff7745fdd8.webp)
状态空间学习之后,根据动作选择函数选择相应动作a并执行,得到环境返还的立即回报r′,环境转换到下一状态s′,此时进行值函数学习,值函数学习之后,当前状态变为s′,重复上述状态空间学习和值函数学习过程,直到学习到最优策略。在线学习过程中,如果设计的算法无法合理地均衡探索和利用,则Agent 会局限在某一块状态区域内,学习到的状态空间表示将会局限在此区域内,同时无法学习到最优策略,因此在值函数学习过程中需要合理地进行探索。
3.2 值函数计算
考虑满足所做假设的强化学习问题,在Agent 与环境交互过程中,假设某一时刻状态为s,此时需要计算该状态对应的状态行为值来进行动作选择。在计算具体的状态行为值Q(s,a)时,使用该时刻列表D中当前状态s的k个近邻点相应的状态行为值来估计Q(s,a)。假设当前列表D={x1,x2,…,xn},n≤Nmax,动作集合为A={a0,a1,a2},则状态s在状态空间表示点中的k个近邻点如图1 所示(图中仅表示出D中的一部分点)。
则状态s的k近邻集合表示为:
![图片[6]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172509-686ff775c5d68.webp)
分别计算K(s)中k个近邻点x1,x2,…,xk与s的距离:
![图片[7]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172511-686ff7774c048.webp)
![图片[8]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172512-686ff778c23f2.webp)
Fig.1 k neighborhoods of s(k=4)图1 状态s 的k 近邻(k=4)
得到K(s)相对应的距离集合,表示为:
![图片[9]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172514-686ff77a462bc.webp)
同时计算权重集合:
![图片[10]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172516-686ff77c00ccb.webp)
以及近邻点贡献比集合:
![图片[11]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172517-686ff77d86a52.webp)
给定有效近邻点距离阈值d_point,返回k个近邻点中相应距离di≤d_point的近邻点集合,称此近邻点集合为有效近邻点集合,定义为:
![图片[12]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172518-686ff77edc1d4.webp)
状态s的k近邻集合K(s)中与状态s距离大于有效近邻点距离阈值d_point的那些点的集合称为无效近邻点集合,定义为:
![图片[13]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172520-686ff7804884d.webp)
列表D中存放的状态空间表示点对应一张状态行为值表,随着状态空间学习的进行,这张表中的值函数被不断填充和修改。在计算具体的状态行为值Q(s,a)时,使用当前状态s的k个近邻点相应的状态行为值来估计Q(s,a)。在计算时,对于当前状态有效近邻点集合U(s)中的近邻点相应的状态行为值,使用上述状态行为值表中存放的数据;对于当前状态无效近邻点集合R(s)中的近邻点相应的状态行为值,赋值为,因此取值为同时考虑当前状态s的k个近邻点各自的贡献比,则状态行为值计算公式为:
![图片[14]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172521-686ff78196335.webp)
当U(s)=K(s),即R(s)=∅时,称当前状态s是已知的;当U(s)≠K(s),R(s)≠∅,U(s)=∅时,称当前状态s是未知的;否则当前状态s是部分已知的。当前状态已知程度不同,max在(s,a)的计算中所占比重不同。
3.3 值函数更新
考虑满足所做假设的强化学习问题,在Agent 与环境交互的过程中,本算法使用经典的Sarsa 算法来进行值函数更新,Sarsa原始值函数更新公式为:
![图片[15]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172523-686ff78300a65.webp)
其中,在计算具体的状态行为值Q(s′,a′)时,同样使用列表D中状态s′的k个近邻点相应的状态行为值来估计Q(s′,a′),根据式(2)得:
![图片[16]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172524-686ff784bec83.webp)
![图片[17]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172526-686ff786c110d.webp)
因此,本文算法值函数更新公式变为:
![图片[18]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172528-686ff78832287.webp)
上式可以看作是传统RMAX 算法[10]在连续状态空间上不确定性度量的拓展,在传统RMAX 算法中,某一状态的已知程度的取值是布尔型数值,此状态已知时,对其进行正常的状态行为值更新;当其未知时,更新量变为而本文算法中对传统RMAX进行扩展,根据状态已知程度赋予不同程度的更新量,使探索和利用之间的转换相比传统RMAX 更加平缓,更适用于连续状态空间MDP。
值得注意的是,本文算法无法直接对Q(s,a)进行更新,只能更新当前状态s的k个近邻点对应当前动作a的状态行为值,假设状态s的k近邻集合为:
![图片[19]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172529-686ff78981b0e.webp)
则值函数更新公式变为:
![图片[20]-PAC最优的RMAX-KNN探索算法*-游戏花园](https://www.hunggame.com/wp-content/uploads/2025/07/20250710172530-686ff78ac895b.webp)
从上述值函数更新公式可以看出,在Agent 与环境交互的每一步更新时,仅仅更新当前状态的k个近邻点对应当前动作的状态行为值,这样算法的学习效率不太理想。联想经典强化学习算法,使用资格迹来提升本文算法性能。
3.4 资格迹的引入
资格迹的引入可以极大地提升时间差分算法的性能[1]。传统时间差分算法在每一步进行值函数更新时,仅仅更新当前状态的值函数;而资格迹的引入使得值函数每一步的更新扩散到之前Agent 经历过的所有状态中。资格迹由一个取值在0 到1 的变量λ来控制,当λ等于0 时,带有资格迹的时间差分算法就是传统的时间差分算法,即不带有资格迹的时间差分算法;当λ等于1 时,此时带有资格迹的时间差分算法就等效于蒙特卡罗算法。
在本文算法中引入资格迹,就必须为所有的状态空间表示点分配一个矩阵e来存放每个状态空间表示点的迹。使用资格迹之后,本文算法在每次进行值函数更新时,值函数更新的范围将不仅仅局限于当前状态的k个近邻点,而是扩散到目前所学习到的所有状态空间表示点,此时值函数更新公式变为:
![图片[21]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723lzibygf2y01.webp)
其中,替代资格迹e更新公式如下:
![图片[22]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723rn13lofrlzh.webp)
其中,P(s)是状态s相对应的近邻点贡献比集合,a是Agent 在当前状态s所执行的动作。通常资格迹e会以下式衰减:
![图片[23]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723ggypbhmufng.webp)
结合状态空间学习、值函数计算、引入资格迹的值函数更新三部分,就得到了本文所提算法,算法的主要步骤总结如下:
算法1 RMAX-KNN
输入:最大离散状态数Nmax,距离阈值d_target,离散动作集合A,近邻点数k,有效近邻点距离阈值d_point,最大回合数max_episode,最大步数max_step。
输出:最优策略。
步骤1初始化列表D为空,建立Nmax行A列的Q表,表中所有元素初始化为max;同时建立相同大小的e表,表中所有元素初始化为0。
步骤2当回合数小于max_episode时,在每一回合中重复以下步骤:
步骤2.1回合开始时由环境自带的reset 函数给定初始状态。
步骤2.2在当前状态下根据式(2)计算相应值函数,然后通过贪婪策略选取并执行动作,转移到下一状态,在下一状态同样根据式(2)计算值函数并选取相应动作。
步骤2.3根据式(1)对当前状态进行状态空间学习,同时根据式(5)进行值函数更新。
步骤2.4将下一状态变为当前状态,返回步骤2.2,重复以上步骤直到本回合终止。
步骤3当最大回合数完成时,算法结束。
4 RMAX-KNN 算法的PAC-MDP 证明
在对RMAX-KNN 算法进行分析之前,首先简要介绍一下PAC-MDP 相关定义。
4.1 PAC-MDP
PAC-MDP 是一种强化学习算法的度量准则,用于约束强化学习算法所学策略没有逼近最优策略的总时间步数。这一准则最早被Fiechter 在文献[11]中引入到强化学习中,之后被Kearns、Singh 在文献[12]和Kakade 在文献[13]以及Strehl 在文献[14]分别重新定义。本文使用Strehl在文献[14]中定义的PAC-MDP概念,定义如下:
定义1[14]令ht=(s0,a0,r1,s1,a1,…,st) 表示由一强化学习算法A 到时间t生成的路径,令πt表示t时刻算法学习到的策略。对于任意给定的参数ϵ>0,算法A 学习到的策略没有逼近最优策略,即满足Vπt(st)≤V*(st)-ϵ的总时间步数定义为算法A 的样本复杂度。
定义2[14]根据定义1,某一算法A 的样本复杂度是用算法所学策略没有逼近最优策略的总时间步数来度量。在离散状态空间MDP 中(假设动作空间离散),如果算法A 的样本复杂度可以由MDP 状态和动作总数量的多项式表示,则称算法A 是满足PACMDP 的强化学习算法。
定义1 和定义2 分别是针对离散状态空间MDP问题所定义的样本复杂度和PAC-MDP 准则。在连续状态空间MDP 中,状态数量为无限多,定义2 不再适用,因此本文使用文献[9]中连续状态空间的覆盖数概念,同时基于此概念给出连续状态空间下的PAC-MDP 准则,定义如下:
定义3[9]连续状态空间MDP(假设动作空间离散)中,假设此MDP 中所有从初始状态可达的状态行为对都包含于集合U中,存在集合C满足:
![图片[24]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723ffigxbhmzxr.webp)
其中,d是一种距离度量方式,r是给定的距离阈值。若集合C最小时元素个数为NU(r),则称NU(r)为集合U的覆盖数。在连续状态空间MDP 中,集合U对应SA,则NSA(r)称为连续状态空间MDP 状态行为空间的覆盖数。
定义4[9]在连续状态空间MDP(假设动作空间离散)中,如果算法A 的样本复杂度可以由此MDP 状态行为空间的覆盖数NSA(r)的多项式表示,则称算法A 在此连续状态空间MDP 上满足PAC-MDP 准则。
4.2 PAC-MDP 证明
本文算法样本集合,即状态空间表示点集合中存放的仅仅是状态,并非状态行为对,在状态空间学习完成之后,样本集合中的状态空间表示点可以代表当前MDP 的整个连续状态空间,联系定义3 和状态空间学习,此时D中元素数量为当前MDP 状态空间S的覆盖数,记为NS(d_point)。本文算法根据这NS(d_point)个状态空间表示点建立了一张相应的状态行为值表,其中每个元素分别对应一个状态行为值并初始化为max,这样在计算当前状态的状态行为值来进行动作选择时,如果当前状态存在无效近邻点集合,则值函数计算公式为:
![图片[25]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723y3bkg5xtzv1.webp)
若当前状态不存在无效近邻点集合,则值函数计算公式变为:
![图片[26]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723yexd5fn1p34.webp)
但当前状态的k近邻集合对应的状态行为值如果没有更新一直是初始值max,则此时值函数计算公式与存在无效近邻点集合时相一致。本文算法通过判断当前状态s的k近邻集合是否等于其有效近邻点集合来衡量当前状态行为对是否已知,此时判断条件为:
![图片[27]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011723boycpdlxs4b.webp)
可见其实是计算状态行为对之间的距离,只是所取动作相同。在本文算法中,对于当前MDP,NSA(d_point)=A×NS(d_point)。
在对本文算法进行PAC-MDP 分析前,首先阐述相关引理和定理。
引理1[15]最多添加kNSA(d_point)个样本可以使所有从初始状态可达的状态行为对变为已知。
引理2[12]如果,则Vπ(s,T)-Vπ(s)≤
引理3[16]令M表示一个MDP,K表示一个状态行为对的集合,M′表示一个在集合K中所有状态行为对上与M具有相同状态转移函数和回报函数的MDP,π表示一个策略,T为任一正整数。令AM表示在M中从状态s1开始遵循策略π与环境交互T步生成的路径中遇到一个不在集合K中的状态行为对这一事件。则:
![图片[28]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011724dbtwc1wu1rt.webp)
引理4[17]令x1,x2,…∈B 表示一个由m个独立伯努利实验组成的序列,其中每个实验成功概率均大于等于μ:E[xi]≥μ,μ>0 。给定任意实数l∈N和δ∈(0,1),如果,有:
![图片[29]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011724a2chgqjvsfi.webp)
定理1令ε≥0 满足∀(s,a)∈(S,A),(s,a)-Q(s,a)≤ε,且V*(s)≤V,则在值函数上采用贪婪策略所得回报Vπ满足:
![图片[30]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011724qjzyr41wzwj.webp)
定理1 的证明见附录。
本文算法在进行值函数更新时,采用带有资格迹的时间差分算法。为了方便讨论,考虑单步更新的Sarsa算法,原始Sarsa的值函数更新公式如下:
![图片[31]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011724azh4mbduhyj.webp)
当算法状态空间学习完成之后,所有从初始位置可达的状态都为已知状态,此时对于任意状态行为 对(s,a) 和(s′,a′),存 在U(s)=K(s) 和U(s′)=K(s′),根据式(2),计算其状态行为值:
![图片[32]-PAC最优的RMAX-KNN探索算法*-游戏花园](2025071101172424vee2bohdi.webp)
则本文算法值函数更新公式变为:
![图片[33]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011724kkabta3wrzw.webp)
由上式可知,近邻点值函数的更新本质上依旧是在Agent 真实轨迹上进行Sarsa 学习,通过一次次迭代更新,近邻点的值函数收敛并最终逼近于它们各自真实的值函数。但是Agent 真实轨迹中的状态行为对的状态行为值是根据此状态行为对近邻点对应的状态行为值加权平均所得,存在一定误差,导致最终值函数学习完成之后近邻点的值函数也会存在一定的误差。为了方便讨论,这里假设通过本文算法所得到的近邻点状态行为值与其真实的状态行为值之间的误差为εn。
因此,在本文算法中,计算某一状态行为对的值函数时所存在的误差可以被分为两部分:一部分是使用有限数量个近邻点的状态行为值来计算当前状态行为值引入的误差εs;另一部分是近邻点即状态空间表示点各自逼近的状态行为值自身存在的误差εn。
定理2如果那么
定理1 和定理2 分别阐述了本文算法所学状态行为值函数存在的误差与对应状态值函数误差的一致性以及保持所学状态行为值与真实状态行为值差值在某一误差区间内所需充分条件。通过以上引理及定理,可得定理3,如下:
定理3令M表示一个MDP,表示在t时刻根据当前所学状态行为值函数采取贪婪策略所得到的策略,st表示t时刻时的状态,并且k≥对于一个任意长度的轨迹,当
![图片[34]-PAC最优的RMAX-KNN探索算法*-游戏花园](2025071101172524pmbs3mk4h.webp)
有:
![图片[35]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725rpcv0c2zpus.webp)
通过定理3 可知从初始状态开始,本文算法逼近最优策略所需总时间步数t可以由连续状态空间MDP 的覆盖数NSA(d_point)的多项式表示,因此本文算法满足PAC-MDP 准则。
定理2 和定理3 的相关证明见附录。
5 实验与结果
在3个经典强化学习环境Mountain Car、Cart Pole、Inverted Pendulum 上测试本文算法,算法的源代码地址为https://github.com/chaobiubiu/RMAX-KNN。
5.1 Benchmark domains
Mountain Car:在此环境中,Agent 的目标是让一个动力不足的小车在来回跑动后可以到达右侧山顶。小车的状态空间是连续的,分为两个维度,第一个是小车所在位置position∈[-1.2,0.6],第二个是小车当前速度velocity∈[-0.07,0.07];小车的动作空间是离散的A={0,1,2},动作0 代表给小车一个向左的力,动作1 代表不施加力,动作2 代表给小车一个向右的力。小车初始位置在山谷最低处,问题的难度在于从初始位置给小车直接施加向右的力小车是无法到达右侧山顶的,小车只有先往左走然后获得一定的动能,才可以到达右边目标点。在小车没有到达目标点之前,小车每走一步所获得的奖励一直是-1,只有到达目标点获得奖励为0。实验参数设置为:总回合数为500,每个回合最大步数为1 000,学习率α=0.9,折扣因子γ=0.99,资格迹衰减参数λ=0.95。学习率、折扣因子以及资格迹衰减参数等参数的设置参考文献[18],每一回合开始时小车位置由gym 环境自带的reset函数初始化。
Cart Pole:在此环境中,存在一个小车,小车上方竖着一根杆子,Agent 的目标就是左右移动这个小车来保持杆子竖直。如果杆子的倾斜角度大于15°或者小车左右移动超出了限定范围,此次模拟结束。该环境的状态也是连续的,分为4个维度:第一个是小车的水平位置;第二个是杆子与垂直方向的夹角;第三个是小车的速度;第四个是杆子的角速度。动作空间为离散空间:A={0,1},动作0 代表小车往左走,动作1 代表小车往右走。在保持杆子竖直时,小车每走一步所获得的奖励为1;当杆子过度倾斜或者小车移动超出限定范围时,获得奖励为0。在本文算法中,当杆子过度倾斜或小车移动超出限定范围时,修改获得奖励为-200,这一修改是为了加速算法学习速率,在计算回合平均回报时,仍按照0 来计算。实验参数设置为:总回合数为500,每个回合最大步数为200,学习率α=0.2,折扣因子γ=0.95,资格迹衰减参数λ=0.95。学习率、折扣因子以及资格迹衰减参数等参数的设置参考文献[18],开始位置由gym环境自带的reset 函数初始化。当100个连续回合内所得平均奖励大于195 时,认为该问题被解决。
Inverted Pendulum:在此环境中,电机需要来回摆动钟摆来收集能量,最终将钟摆抬高并保持钟摆平衡。状态空间分为3个维度:第一个是当前钟摆与垂直方向夹角的余弦值cos(theta)∈[-1,1];第二个是当前钟摆与垂直方向夹角的正弦值sin(theta)∈[-1,1];第三个是当前钟摆的角速度thetadot∈[-8,8],动作空间为连续空间A={a-2 ≤a≤2}。实验参数设置为:总回合数为500,每个回合最大步数为500,学习率α=0.9,折扣因子γ=0.95,资格迹衰减参数λ=0.95。学习率、折扣因子以及资格迹衰减参数等参数的设置参考文献[19],开始位置初始化为[1,0,0],同时参考文献[20],将环境的立即回报函数修改为reward=1-exp[-xTdiag([1,0.2])x]。
5.2 实验结果
实验中,首先考察了算法中3个参数k、d_target、d_point对算法性能的影响,然后与采用Tilecoding 编码的Sarsa(λ)算法进行比较。
(1)参数对算法性能的影响
本文算法中有3个参数k、d_target、d_point,其中k的取值决定了计算当前状态行为对的状态行为值时所选近邻点的个数,k取值太小,当前状态行为值逼近效果差;k取值太大,当前状态行为值逼近误差过大,难以达到实验目标。d_target的取值决定了对于状态空间的划分精度,d_target取值小,划分精度高,最终算法收敛效果好,但是收敛速度慢;d_target取值大,划分精度低,最终算法收敛速度快,但是收敛效果较差。d_point是有效近邻点距离阈值,衡量一个状态行为对未知程度的参数,d_point取值小,如果状态空间划分精度低,则Agent 在算法学习过程中遇到的状态行为对全部变为已知需要很长时间,造成算法难以收敛最终学习失败;d_point取值大,如果状态划分精度高,则Agent 遇到的所有状态行为对在较短的时间内可以变为已知,算法收敛速度很快,但是收敛效果较差。参数k、d_target、d_point彼此之间相互影响,图2、图3、图4 分别是固定其中两个参数,调整另外一个参数对于算法性能影响的实验结果图。
![图片[36]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725plz32vwuisd.webp)
Fig.2 Effect of k on algorithm图2 k 值对算法的影响
图2(a)中横坐标为回合数,纵坐标为每个回合内小车到达目标点所需步数,所需步数越少越好。从图中可以看出:当k取值为1 时,算法性能波动较大,算法性能差;当k取值为3 或5 时,算法快速收敛且收敛效果极好;当k取值为7 或9 时,小车无法达到目标点,算法难以学习到最优策略。图2(b)中横坐标为回合数,纵坐标为每个回合的平均回报,平均回报越高越好。从图中可以看出:当k取值为1 时,算法难以学习到最优策略;当k取值为3 时,算法可以快速收敛且收敛效果极好;当k取值为5、7、9 时,算法收敛速度较慢且收敛结果较差。图2(c)中横坐标为回合数,纵坐标为每个回合内获得的总回报,总回报越高越好。从图中可以看出:当k取值为1 时,算法收敛速度较慢且收敛效果较差;当k取值为3 时,算法快速收敛且收敛效果极好;当k取值为5、7、9 时,算法性能波动较大,算法性能差。
![图片[37]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725zepgamvalsu.webp)
Fig.3 Effect of d_target on algorithm图3 d_target值对算法的影响
![图片[38]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725we104jfr4w3.webp)
Fig.4 effect of d_point on algorithm图4 d_point值对算法的影响
图3(a)中横坐标为回合数,纵坐标为每个回合内小车到达目标点所需步数,所需步数越少越好。从图中可以看出:当d_target取值为0.05 或0.07 时,算法性能波动较大;当d_target取值为0.09 或0.11时,算法快速收敛且收敛效果较好;当d_target取值在0.13 时,算法性能差。图3(b)中横坐标为回合数,纵坐标为每个回合的平均回报,平均回报越高越好。从图中可以看出:当d_target取值为0.03 时,算法收敛速度较慢;当d_target取值为0.05 或0.07 时,算法可以快速收敛且收敛效果极好;当d_target取值为0.09 或0.11 时,算法性能差。图3(c)中横坐标为回合数,纵坐标为每个回合内获得的总回报,总回报越高越好。从图中可以看出,当d_target取值为0.03、0.05、0.07 时,算法性能最优;当d_target取值为0.06或0.08 时,算法性能差。
图4(a)中横坐标为回合数,纵坐标为每个回合内小车到达目标点所需步数,所需步数越少越好。从图中可以看出:当d_point取值为0.10 时,算法难以学习到最优策略;当d_point取值为0.12 或0.14 时,算法性能波动较大;当d_point取值为0.16 时,算法可以快速收敛且收敛效果极好;当d_point取值为0.18 时,算法收敛速度较慢且收敛效果较差。图4(b)中横坐标为回合数,纵坐标为每个回合的平均回报,平均回报越高越好。从图中可以看出:当d_point取值为0.07 时,算法难以学习到最优策略;当d_point取值为0.09、0.13 时,算法收敛速度较慢且收敛效果较差;当d_point取值为0.11、0.15 时,算法快速收敛且收敛速度极好。图4(c)中横坐标为回合数,纵坐标为每个回合内获得的总回报,总回报越高越好。从图中可以看出:当d_point取值为0.06、0.07 时,算法性能较差;当d_point取值为0.09、0.11、0.13 时,算法快速收敛且收敛效果极好。
(2)本文算法与采用Tilecoding 编码的Sarsa(λ)算法的比较
![图片[39]-PAC最优的RMAX-KNN探索算法*-游戏花园](202507110117253fbwnwskh2v.webp)
Fig.5 Comparison result of two algorithms图5 两种算法实验对比结果
为进一步验证本文算法的性能,与采用Tilecoding编码的Sarsa(λ) 算法进行比较,比较结果如图5 所示。在Mountain Car 问题中,本文算法在多次实验之后选取最优参数k=3,d_target=0.09,d_point=0.16;而对比实验中采用20×20 的表格对二维状态空间进行划分,分别设置Tilings=5、10、20,对比结果如图5(a)所示。图中横坐标表示回合数,纵坐标表示每个回合中小车到达目标点所需步数(如果所需步数为实验所设最大步数,则表示此回合小车没有到达目标点),所需步数越少,则实验结果越好。相比之下,本文算法更快收敛且收敛效果更好(到达目标点最优步数为83 步),而对比算法收敛较慢且收敛效果较差(到达目标点最优步数为113 步)。在Cart Pole 问题中,同样在多次实验之后本文算法选取最优参数k=3,d_target=0.07,d_point=0.11;对比实验中采用20×20×20×20 的表格对四维状态空间进行划分,分别设置Tilings=5、10、20,对比结果如图5(b)所示。图中横坐标表示回合数,纵坐标为每个回合的平均回报,平均回报越高实验结果越好。相比之下,本文算法最优平均回报为200,表现远远优于对比算法(对比算法最优平均回报为125)。在Inverted Pendulum 问题中,在多次实验之后选取最优参数k=3,d_target=0.05,d_point=0.09;对比实验中采用20×20×20 的表格覆盖三维状态空间,分别设置Tilings=5、10、20,对比结果如图5(c)所示。图中横坐标表示回合数,纵坐标表示每个回合中所获得的总回报,总回报越高实验结果越好。相比之下,本文算法可以快速收敛且收敛效果优秀(收敛之后每个回合总回报为-0.26),而对比算法收敛较慢且收敛结果略差(收敛之后每个回合总回报最优为-0.68)。此外,本文算法在达到实验目标时所学到的状态空间表示点数量分别为:Mountain Car 环境下状态空间表示点数量为239个;Cart Pole 环境下状态空间表示点数量为220个;Inverted Pendulum 环境下状态空间表示点为1 016个,远小于对比实验中离散状态空间点的个数,降低了算法的空间复杂度。
表1 为在各自最优参数下本文算法与采用Tilecoding 编码的Sarsa(λ)算法回报rew、点数num以及收敛所需回合数epi的比较。
![图片[40]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725zm0rg2mdmov.webp)
Table 1 Comparison result of two algorithms表1 两种算法对比实验结果
从表1 中可以看出,在回报方面,本文算法在Mountain Car、Cart Pole、Inverted Pendulum 环境下所得回报均大于对比算法所得回报,回报越高,则算法性能越好;在状态空间表示点数目方面,本文算法在3个实验环境下达到实验目标所需状态空间表示点数目均远远小于对比算法,点数越少则算法空间复杂度越低;在收敛所需回合数方面,本文算法在3个实验环境下收敛所需回合数均远小于对比算法,收敛所需回合数越少则算法时间复杂度越低,性能越好。综合以上三方面,可知本文算法性能远优于对比算法。
6 结束语
本文提出的基于状态空间自适应离散化的RMAXKNN 强化学习算法在值函数学习中嵌入了探索与利用的均衡,同时实现了状态空间的自适应离散化。该算法通过改写值函数形式,使探索与环境状态空间离散化相结合,逐步加深Agent 对于环境的认知程度,极大地提升了探索效率,降低了时间复杂度;同时自适应离散化环境状态空间,降低了空间复杂度。本文提出的算法可以在一定程度上缓解维数灾难,但当连续状态空间维度很高时,维数灾难仍会加重,未来将致力于在值函数逼近和策略搜索两者结合的Actor Critic 方法及其一系列变种方法中实现探索与利用的均衡。
附录
定理1令ε≥0 满足∀(s,a)∈(S,A),(s,a)-Q(s,a)≤ε,且V*(s)≤V,则在值函数上采用贪婪策略所得回报Vπ满足:
![图片[41]-PAC最优的RMAX-KNN探索算法*-游戏花园](2025071101172504vbhlt2t5l.webp)
证明∀(s,a)∈(S,A),(s,a)-Q(s,a)≤ε,则∀(s,a)∈(S,A),(s,a)-Q*(s,a)≤ε。由贝尔曼最优方程V*(s)=maaxQ*(s,a)可得:
![图片[42]-PAC最优的RMAX-KNN探索算法*-游戏花园](202507110117252b2conb15iz.webp)
定理得证。 □
定理2如果,那么:
![图片[43]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725ugmwxkwuelt.webp)
证明是式(2)的唯一且固定解,(s,a)是状态行为对(s,a)的k个近邻点对应于当前动作a的状态行为值加权平均所得值,Q(s,a)是状态行为对(s,a)的真实状态行为值,则:
![图片[44]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011725q4s1mnprm5g.webp)
可见对(s,a)的k个近邻点对应的状态行为值进行加权平均计算出(s,a),而本文算法中近邻点逼近的状态行为值存在误差εn,即:
![图片[45]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726jzwoomqcbaw.webp)
其中,Q(xi,a)为近邻点真实的状态行为值。考虑使用有限数量个近邻点的真实状态行为值来计算当前状态行为值引入的误差εs,即:
![图片[46]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726s1zykjr2r2p.webp)
当上式中pi取时,由Hoeffding 不等式得:
![图片[47]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726akua5azrq3z.webp)
考虑pi不为的情况,此时由Hoeffding 不等式的一般形式可得:
![图片[48]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726bftqo3x0bb4.webp)
由定义3 可知,连续状态空间MDP 中所有从初始状态可达的状态行为对都可以由此MDP 状态动作空间的覆盖数来表示,因此NSA(d_point)个样本可以代表所有从初始状态可达的状态行为对。而所有从初始状态可达的状态行为对的状态行为值是根据其k个近邻点相应的状态行为值来计算,等价于这NSA(d_point)个样本每个都取k次来评估各自代表的状态行为对,因此所有从初始状态可达的状态行为对根据各自近邻点状态行为值加权平均所得的状态行为值与其真实状态行为值的差值大于等于(εs+εn)的概率δ满足:
![图片[49]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726vzbofudg2av.webp)
因为k≥1,所以:
![图片[50]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726fwtv20pwpa5.webp)
给定概率δ和误差εs和εn,由上式得:
![图片[51]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726dm4oucarjhm.webp)
定理得证。 □
定理3令M表示一个MDP,表示在t时刻根据当前所学状态行为值函数采取贪婪策略所得到的策略,st表示t时刻时的状态,并且对于一个任意长度的轨迹,当
![图片[52]-PAC最优的RMAX-KNN探索算法*-游戏花园](20250711011726qd22kljukwn.webp)
证明令M′表示一个在所有已知状态行为对上状态转移函数与M相同的MDP,假设其他状态行为对都可以确定性转移到一个假设存在的状态s*,该状态状态值为0,且所得回报为R(s,a)=(s,a)。令AM表示在T时间步数内遇见一个未知状态行为对这一事件。在每一时间步时,仅会发生下述两件事之一:
(2)对于t时刻的状态st,,则:
![图片[53]-PAC最优的RMAX-KNN探索算法*-游戏花园](202507110117260uz3jwl0z5l.webp)
定理得证。 □